
9.深層学習の適応方法ー音声処理
WaveNetは、音声生成タスクにおいて革新的な成果を達成したディープラーニングモデルです。以下にWaveNetの特徴を5つご紹介します:
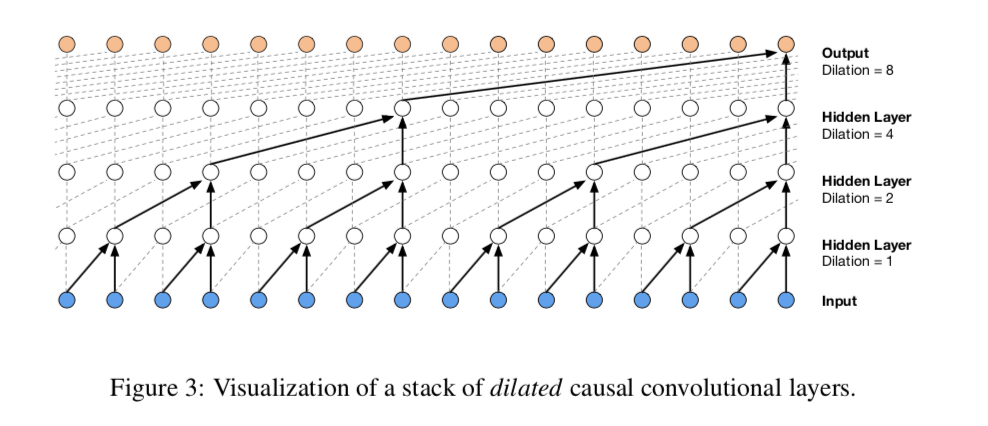
- WaveNetは深層畳み込みニューラルネットワークです。通常の畳み込み層では大きな範囲の情報をカバーできませんが、WaveNetでは長い履歴を捉えるために大きな受容野を持つ畳み込み層が使用されます。
- サンプリング精度の向上: WaveNetは、伝統的な音声合成技術に比べて高いサンプリング精度を提供します。これにより、より自然でリアルな音声合成が可能になります。
- 非常に多いパラメータ数: WaveNetは非常に深いネットワーク構造と大量のパラメータを持っています。これは高い音質を実現する一方で、学習に多くの計算リソースと時間を要します。
- インクリメンタル音声生成: WaveNetは、入力された音声に対して一部のテキストを入力することで、残りの音声を生成することができる「インクリメンタル音声生成」を可能にします。
- 音声合成の高品質化: WaveNetは高品質な音声を生成するために、非常に自然な音声合成を行います。この特徴により、TTS(テキスト・トゥ・スピーチ)技術や音声アシスタントなどの領域で広く利用されています。
論文のアブストラクト
This paper introduces WaveNet, a deep neural network for generating raw audio
waveforms. The model is fully probabilistic and autoregressive, with the predictive distribution for each audio sample conditioned on all previous ones; nonetheless we show that it can be efficiently trained on data with tens of thousands of
samples per second of audio. When applied to text-to-speech, it yields state-ofthe-art performance, with human listeners rating it as significantly more natural
sounding than the best parametric and concatenative systems for both English and
Mandarin. A single WaveNet can capture the characteristics of many different
speakers with equal fidelity, and can switch between them by conditioning on the
speaker identity. When trained to model music, we find that it generates novel and
often highly realistic musical fragments. We also show that it can be employed as
a discriminative model, returning promising results for phoneme recognition
chatGPTで翻訳かつ要約すると、
この論文はWaveNetを紹介しており、音声波形を生成するための深層ニューラルネットワークです。
このモデルは完全に確率的であり、オートレグレッシブ(自己回帰)で、各オーディオサンプルの予測分布はこれまでのすべてのサンプルに依存しています。
それにもかかわらず、音声の1秒あたり数万サンプルのデータで効率的にトレーニングできることを示しています。
テキスト読み上げに適用すると、英語と中国語(Mandarin)の両方で、最高のパラメトリックと連結系のシステムよりも著しく自然な音質と評価される、最先端の性能を実現します。
1つのWaveNetは多くの異なる話者の特性を同じ品質で捉えることができ、話者の識別によってそれらを切り替えることもできます。
音楽のモデル化にも使用でき、新しいかつ高いリアリティのある音楽フラグメントを生成することが分かりました。
さらに、識別モデルとしても使用でき、音素認識において有望な結果を示しています。