
VQ-VAEもVAE(Variational AutoEncoder)と同じで潜在変数を使った画像などの生成モデル
論文はこちら→https://arxiv.org/abs/1711.00937
目次
VQ-VAE(Vector Quantized Variational Autoencoder)とは
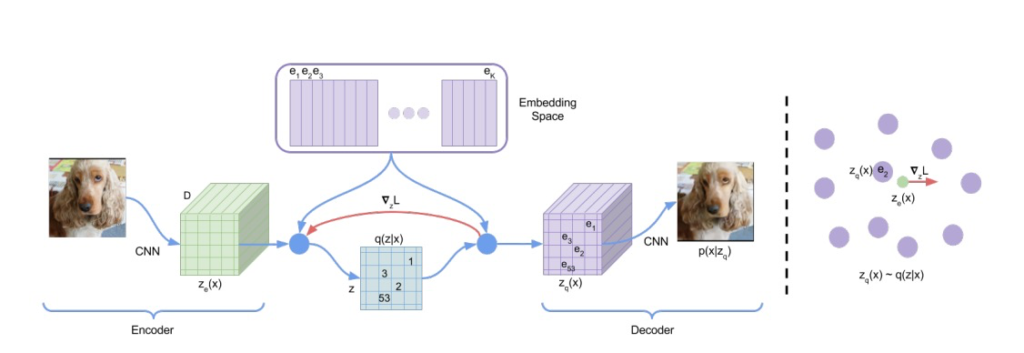
VQ-VAE(Vector Quantized Variational Autoencoder)は、画像や音声などの信号データに対して高次元の表現を学習するための変分オートエンコーダの一種です。
- ベクトル量子化:VQ-VAEでは、離散的なコードブックを使用して高次元のデータを低次元の離散的な表現に量子化します。これにより、データの効率的な表現と高次元特徴の圧縮を実現します。
- 厳密な再構成:VQ-VAEは、再構成誤差を最小限に抑えるように学習されます。量子化コードを使って再構成するため、厳密な再構成が可能であり、高品質なデータ再現が実現されます。
- 非常に表現力のあるモデル:VQ-VAEは、高い表現力を持つ深層ネットワークモデルであり、データの複雑な特徴を捉えることができます。これにより、高品質な生成や特徴抽出が可能になります。
- 潜在空間の意味のある表現:VQ-VAEの潜在空間には、データの意味のある表現がエンコードされます。この潜在空間を操作することで、データの意味のある変換や合成が実現できます。
- 生成モデルとしての利用:VQ-VAEは高品質なデータ再現ができるため、画像や音声の生成モデルとしても利用されます。潜在空間からサンプリングすることで、新しいデータの生成が可能となります。
論文のアブストラクト
Learning useful representations without supervision remains a key challenge in
machine learning. In this paper, we propose a simple yet powerful generative
model that learns such discrete representations. Our model, the Vector QuantisedVariational AutoEncoder (VQ-VAE), differs from VAEs in two key ways: the
encoder network outputs discrete, rather than continuous, codes; and the prior
is learnt rather than static. In order to learn a discrete latent representation, we
incorporate ideas from vector quantisation (VQ). Using the VQ method allows the
model to circumvent issues of “posterior collapse” -— where the latents are ignored
when they are paired with a powerful autoregressive decoder -— typically observed
in the VAE framework. Pairing these representations with an autoregressive prior,
the model can generate high quality images, videos, and speech as well as doing
high quality speaker conversion and unsupervised learning of phonemes, providing
further evidence of the utility of the learnt representations.
chatGPTで翻訳
教師なし学習において、有用な表現を学習することは機械学習における主要な課題です。
この論文では、そのような離散的な表現を学習する、シンプルでありながら強力な生成モデルを提案します。
私たちのモデル、Vector Quantised Variational AutoEncoder(VQ-VAE)は、VAE(Variational AutoEncoder)とは異なり、エンコーダーネットワークが連続的なコードではなく離散的なコードを出力します。
また、事前分布は固定されたものではなく、学習によって決定されます。
離散的な潜在表現を学習するため、ベクトル量子化(VQ)のアイデアを取り入れています。
VQの手法を使用することで、モデルはVAEのフレームワークで一般的に観察される「posterior collapse」の問題を回避できます。
これにより、強力なオートリグレッシブデコーダーと対応する際に、潜在表現が無視されることが防がれます。
これらの表現をオートリグレッシブ事前分布と組み合わせることで、モデルは高品質の画像、動画、音声を生成するだけでなく、高品質の話者変換や音素の教師なし学習も実現できます。
これらは学習された表現の有用性をさらに裏付けています。
VQ-VAEの損失関数
VQ-VAEの損失関数は、次のような数式で表されます:
L = recon_loss + beta * commitment_loss
ここで、
- recon_lossは再構成誤差を表します。オートエンコーダーの一般的な損失関数として、入力データと再構成データの間の誤差を測定します。
- commitment_lossはコードブックの重みを更新するための損失関数です。これは、エンコーダーの出力と最寄りのコードブックの要素との距離を計算し、コードブックの要素に近づくようにエンコーダーを学習することを促す効果があります。
- betaは、コードブック更新の強さを調整するハイパーパラメータです。コードブックの更新が再構成誤差に比べてどれだけ重要かを調整する役割を果たします。
この損失関数により、VQ-VAEはデータの再構成誤差と離散的なコードブックの学習の両方を考慮して、有用な表現を学習することができます。
VQ-VAEをPytorchで実装
chatGPTにおねがいしてみた
import torch
import torch.nn as nn
import torch.nn.functional as F
class VectorQuantizer(nn.Module):
def __init__(self, num_embeddings, embedding_dim, commitment_cost):
super(VectorQuantizer, self).__init__()
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
self.commitment_cost = commitment_cost
# Codebook
self.embedding = nn.Embedding(num_embeddings, embedding_dim)
def forward(self, inputs):
# Flatten the inputs
input_shape = inputs.shape
inputs = inputs.view(-1, self.embedding_dim)
# Compute distances between inputs and codebook vectors
distances = torch.cdist(inputs.unsqueeze(1), self.embedding.weight.unsqueeze(0))
# Find the nearest codebook vectors
indices = torch.argmin(distances, dim=1)
# Quantized codes
quantized = self.embedding(indices).view(input_shape)
# Compute loss
e_latent_loss = F.mse_loss(quantized.detach(), inputs)
q_latent_loss = F.mse_loss(quantized, inputs.detach())
commitment_loss = self.commitment_cost * e_latent_loss
# Quantization loss and codebook indices
quantization_loss = q_latent_loss + commitment_loss
return quantized, quantization_loss, indices
class VQVAE(nn.Module):
def __init__(self, num_embeddings, embedding_dim, commitment_cost):
super(VQVAE, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, 64, 4, 2, 1),
nn.ReLU(),
nn.Conv2d(64, 128, 4, 2, 1),
nn.ReLU(),
# Add more layers as needed
)
self.decoder = nn.Sequential(
# Add more layers as needed
nn.ConvTranspose2d(128, 64, 4, 2, 1),
nn.ReLU(),
nn.ConvTranspose2d(64, out_channels, 4, 2, 1),
nn.Sigmoid() # Use Sigmoid for image generation
)
self.vector_quantizer = VectorQuantizer(num_embeddings, embedding_dim, commitment_cost)
def forward(self, x):
z = self.encoder(x)
quantized, quantization_loss, indices = self.vector_quantizer(z)
recon_x = self.decoder(quantized)
return recon_x, quantization_loss
# モデルのインスタンスを作成
in_channels = 3 # 入力画像のチャンネル数
out_channels = 3 # 出力画像のチャンネル数
num_embeddings = 512 # コードブックの要素数
embedding_dim = 64 # コードブックの次元数
commitment_cost = 0.25 # コードブックの更新強度
vq_vae = VQVAE(num_embeddings, embedding_dim, commitment_cost)
このプログラムは、VQ-VAE(Vector Quantized Variational AutoEncoder)と呼ばれるモデルをPyTorchを使用して実装しています。VQ-VAEは、高次元のデータを離散的な表現に変換するための変分オートエンコーダの一種です。
プログラムの内容を以下に説明します:
VectorQuantizerクラス:
- 離散的なコードブックを表現し、コードブックの要素を更新するためのクラスです。
num_embeddingsはコードブックの要素数、embedding_dimはコードブックの次元数、commitment_costはコードブックの更新強度を表すハイパーパラメータです。forwardメソッドでは、入力データに対して最も近いコードブックの要素を探索し、量子化された表現とそれに対する損失を計算します。
VQVAEクラス:
- VQ-VAEのエンコーダとデコーダ、および
VectorQuantizerを組み合わせたモデルのクラスです。 encoderは入力データを潜在表現に変換するエンコーダ部分です。畳み込み層を使用して画像の特徴を抽出します。decoderは潜在表現を再構成画像に変換するデコーダ部分です。畳み込み層を使用して逆畳み込みを行います。vector_quantizerは、前述のVectorQuantizerクラスのインスタンスであり、潜在表現を離散化するために使用されます。forwardメソッドでは、入力データをエンコードし、その潜在表現をvector_quantizerで離散化して、再構成画像と損失を計算します。
- モデルのインスタンス化:
- 最後に、入力画像のチャンネル数
in_channels、出力画像のチャンネル数out_channels、コードブックの要素数num_embeddings、コードブックの次元数embedding_dim、コードブックの更新強度commitment_costを指定して、VQVAEクラスのインスタンスを作成します。
このプログラムは、PyTorchを使用してVQ-VAEのモデルを簡単に実装することができますが、完全な実装にはデータの前処理、トレーニングループ、最適化手法などが必要です。また、実際のタスクによっては、モデルの構造やハイパーパラメータを調整する必要があります。