距離学習(Metric Learning)は、データ間の類似性を測定するための機械学習のアプローチです。特徴空間において、同じクラスに属するデータ間の距離を小さくし、異なるクラスに属するデータ間の距離を大きくするように学習します。これにより、同じクラスのデータは近く、異なるクラスのデータは遠くなるように特徴を学習し、識別やクラスタリングなどのタスクに有用な表現を得ることができます。顔認識や物体検出などの分野で広く応用されています。
距離学習(Metric Learning)の特徴を以下に5つご紹介します:
- 類似性を明確に学習:距離学習は、データ間の類似性を明確に学習することを目的としています。
同じクラスに属するデータは近く、異なるクラスに属するデータは遠くなるように特徴を学習します。 - 教師あり・教師なし学習:距離学習は教師あり学習の一種である場合もありますが、教師なし学習や半教師あり学習の手法としても適用されます。
- 特徴空間の改善:距離学習は、特徴空間において有用な表現を学習することで、識別やクラスタリングなどのタスクの性能を改善します。
- データの不均衡に対応:クラス間のデータの不均衡に対応することができます。
距離学習は、少数のデータに対しても適切な識別性を保つことができます。 - 類似性尺度の定義:距離学習では、類似性を測定する尺度(距離関数)の定義が重要です。
異なる尺度を選択することで、タスクに適した特徴表現を獲得します。
SiameseNet
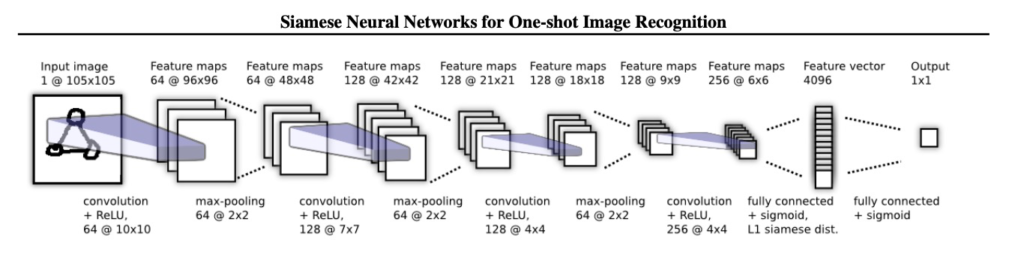
Siamese Network(シャムネット)は、距離学習の一種で、2つの入力サンプルの類似性を評価するためのニューラルネットワークのアーキテクチャです。主な特徴は以下の通りです:
- ペアの入力データ:Siamese Networkは、2つの入力データ(ペア)を並列にエンコードし、それらの特徴表現を得ます。通常、2つの入力データは同じクラス(正例)または異なるクラス(負例)に属することがあります。
- 共有エンコーダ:Siamese Networkの特徴は、共有エンコーダによって抽出されます。2つの入力データは同じエンコーダを使用して特徴に変換され、特徴空間での位置関係を学習します。
- 距離関数による類似性評価:Siamese Networkは、エンコードされた特徴表現を用いて2つの入力データ間の類似性を評価します。通常はユークリッド距離やコサイン類似度などの距離関数を使用します。
- 学習の目的:Siamese Networkは、正例と負例のペアを用いて訓練されます。正例は類似しており、負例は異なるものとして学習します。目的は、正例の特徴を近づけ、負例の特徴を遠ざけるようにエンコーダを学習することです。
- 類似性評価の用途:Siamese Networkは、顔認識、異常検知、文字のペア比較などのタスクで広く使用されます。特に、データのペアごとの類似性を評価する必要がある場合に効果的です。
Contrastive Loss(コントラスティブロス)
\(L(a,p,y)=(1−y)⋅21⋅d(a,p)2+y⋅21⋅max(0,m−d(a,p))2\)TripletLoss
Triplet Loss(トリプレットロス)は、距離学習の一種で、Siamese Networkなどのネットワークで使用される損失関数の一つです。Triplet Lossは、3つのサンプル(Anchor、Positive、Negative)の組み合わせを使用して、特徴空間での類似性を学習するために利用されます。
トリプレットロスは以下のような数式で表現されます:
\(L(a, p, n) = max(d(a, p) – d(a, n) + margin, 0)\) \(L(a,p,n)=max(∥f(a)−f(p)∥ 2 −∥f(a)−f(n)∥ 2 +margin,0)\)ここで、
- aはAnchorサンプルの特徴表現
- pはPositiveサンプルの特徴表現
- nはNegativeサンプルの特徴表現
- d(x, y)は特徴表現xとyの距離を測る関数(例:ユークリッド距離)
- marginはハイパーパラメータで、PositiveサンプルとNegativeサンプルの距離の差がこの値以上である場合にのみロスを計算します
Triplet Lossの目的は、AnchorサンプルとPositiveサンプルの特徴が近く(類似している)なるように学習し、同時にAnchorサンプルとNegativeサンプルの特徴が遠く(類似していない)なるようにエンコーダを学習することです。これにより、特徴空間での類似性を適切に学習することができます。Triplet Lossは、顔認識や特徴埋め込みのようなタスクで一般的に使用されます。