
判断根拠の可視化、モデルの近似
目次
深層学習の説明性や解釈性が必要な理由
深層学習の説明性(Explainability)や解釈性(Interpretability)が必要な理由はいくつかあります:
- 信頼性と安全性:深層学習は非常に複雑なモデルであり、意思決定や予測を行う際にブラックボックスとして振る舞うことがあります。しかし、特に重要な領域(例:医療診断、自動運転)では、モデルの意思決定プロセスが理解可能でなければ信頼性が低くなり、安全性が懸念されることがあります。
- 法律と倫理:特に高リスクのタスク(例:刑事司法、金融予測)において、意思決定の透明性が求められることがあります。説明性や解釈性のあるモデルは、予測の根拠を示すことで法的・倫理的な問題を解決するのに役立ちます。
- 機械学習システムの改善:説明性や解釈性は、モデルの弱点や改善のポイントを特定するのに役立ちます。モデルの動作を理解することで、モデルのパフォーマンス向上に寄与します。
- ユーザーエクスペリエンス:説明性や解釈性があるモデルは、エンドユーザーに対して予測の根拠を説明できるため、受け入れられやすくなります。ユーザーがモデルの動作を理解しやすいことで、信頼性が向上します。
- 市場への導入と規制:一部の業界や市場では、解釈性のあるモデルの使用が法的な要件となることがあります。例えば、金融機関では、クレジットの審査や融資の決定において解釈性が求められることがあります。
これらの理由から、深層学習の説明性や解釈性が重要視される場面が増えており、研究者や産業界でその重要性に対する取り組みが進んでいます。
Grad-CAM
CNNにおいて、画像のどこを見て判断したのかを可視化する方法

Grad-CAM(Gradient-weighted Class Activation Mapping)は、深層学習モデルの解釈性を向上させるための手法の一つです。Grad-CAMは、特に畳み込みニューラルネットワーク(CNN)で分類されるモデルに対して、重要な領域や特徴を可視化することを目的としています。
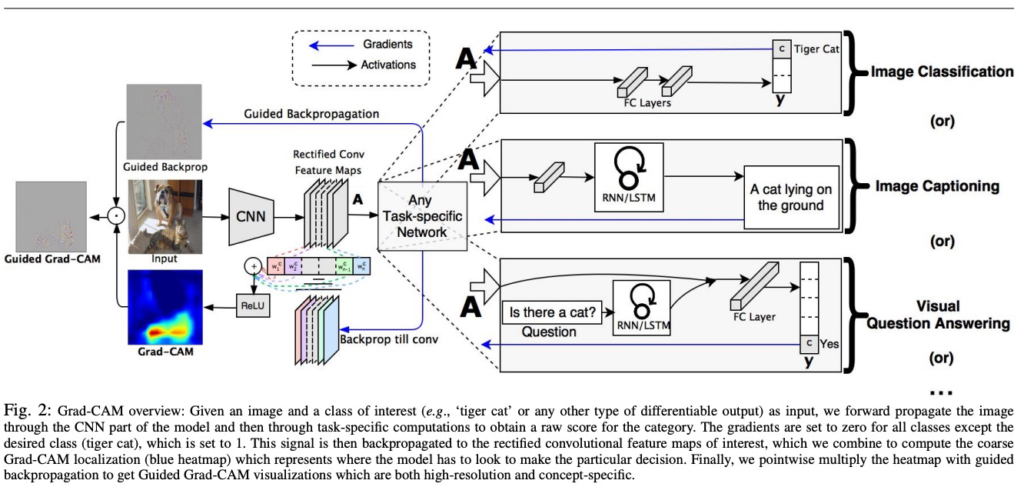
Grad-CAMの主な特徴は以下の通りです:
- 特徴マップの重み付け:Grad-CAMは、特定のクラスに対する予測結果に基づいて、各特徴マップの重要度を計算します。重要度の計算には、クラスに対する予測値の勾配を利用します。
- クラス活性化マップ:Grad-CAMは、重要度の高い領域を強調するために、特徴マップに重みを掛け合わせることで、クラス活性化マップを生成します。これにより、どの部分が予測に対して重要であったかが可視化されます。
- グローバル平均プーリング:Grad-CAMは、特徴マップをグローバル平均プーリングして、特徴マップの空間情報を1つの値に集約します。これにより、個々の特徴マップの重要領域がクラス活性化マップとして可視化されます。
Grad-CAMは、特に複雑なCNNモデルによる予測結果を解釈する際に有用であり、どの特徴が予測に寄与しているかを理解するのに役立ちます。また、医療診断、自動運転、画像認識などの分野でモデルの解釈性を高めるために広く使用されています。
LIME、SHAP モデルの近似
LIME(Local Interpretable Model-agnostic Explanations)とは
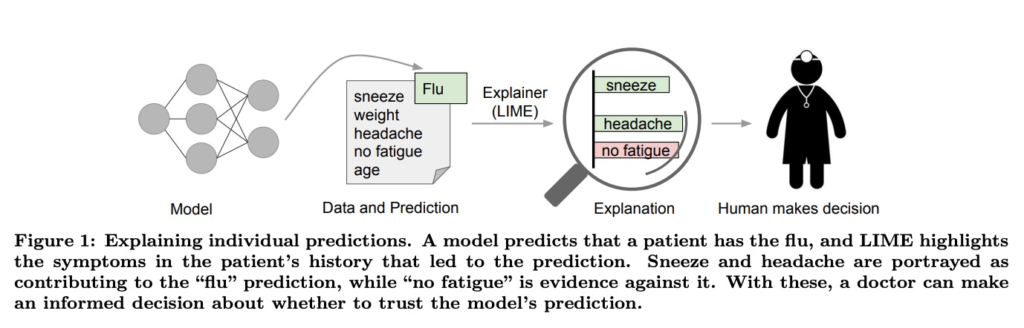
https://arxiv.org/pdf/1602.04938.pdf
LIME(Local Interpretable Model-agnostic Explanations)は、機械学習モデルの解釈性を向上させるための手法の一つです。LIMEは、任意の機械学習モデルに対して適用できる汎用的な解釈手法であり、モデルの予測をローカルなレベルで理解することを目的としています。
LIMEの主な特徴は以下の通りです:
- ローカル解釈性:LIMEは、特定のデータインスタンスに対してモデルの予測をローカルに解釈することを重視しています。つまり、データの周辺領域のみを考慮してモデルの動作を理解します。
- モデル不可知:LIMEは、モデルに対して事前知識を持たない(モデル不可知)手法です。任意の機械学習モデルに対して適用できるため、様々なモデルに対して解釈性を提供します。
- 仮想サンプル生成:LIMEは、特定のデータインスタンスの周囲に仮想的なサンプル(ペルチュルベーション)を生成し、それによってデータの振る舞いを理解します。これにより、モデルがどの特徴を重視して予測を行っているかを推定します。
- ローカルモデルの学習:LIMEは、仮想サンプルを使用してローカルなデータ領域における線形モデルを学習します。このローカルモデルは、元のモデルの予測を近似するために使用され、解釈性を提供します。
LIMEは、特にブラックボックスな機械学習モデルに対して解釈性が必要な場面で有用です。画像認識、自然言語処理、金融予測などのタスクにおいて、モデルの予測を理解しやすくするために広く使用されています。
SHAP(SHapley Additive exPlanations)とは
https://arxiv.org/pdf/1705.07874.pdf
SHAP(SHapley Additive exPlanations)は、機械学習モデルの解釈性を向上させるための手法の一つです。SHAPは、Shapley値という協力ゲーム理論から派生した概念を使用して、特徴の重要度を計算し、モデルの予測を理解することを目的としています。
SHAPの主な特徴は以下の通りです:
- Shapley値に基づく特徴重要度:SHAPは、Shapley値という値を特徴の重要度の計算に使用します。Shapley値は、協力ゲーム理論に基づいて特徴がモデルの予測に対してどれだけ貢献しているかを計算します。
- モデルアゴスティック:SHAPは、任意の機械学習モデルに対して適用できるモデルアゴスティックな手法です。畳み込みニューラルネットワーク(CNN)、ランダムフォレスト、勾配ブースティングなど、さまざまなモデルに対して解釈性を提供します。
- 特徴のインスタンスごとの解釈:SHAPは、各データインスタンスに対して特徴の重要度を計算し、ローカルな解釈性を提供します。つまり、特定のデータポイントの予測を理解することができます。
- 統計的に安定した解釈:SHAPは、特徴の重要度を統計的に安定して計算します。これにより、説明が頼りになるかつ信頼性があることを保証します。
SHAPは、特にブラックボックスモデルや複雑なモデルに対して解釈性が必要な場面で役立ちます。画像分類、自然言語処理、金融予測などの機械学習タスクにおいて、モデルの予測を理解しやすくするために広く使用されています。
Shapley値は、協力ゲーム理論に基づいて計算される値で、特徴がゲームにおいてどれだけ貢献しているかを示します。特徴(i)のShapley値は以下のように計算されます:
\(\phi_i(v) = \sum_{S \subseteq N \setminus {i}} \frac{|S|!(|N|-|S|-1)!}{|N|!} \left[ v(S \cup {i}) – v(S) \right]\)ここで、
- \(\phi_i(v)\)は特徴(i)のShapley値を表します。
- \(v(S)\)は特徴の部分集合(S)を使ったときのゲームの価値を表します。
- (N)は特徴の全集合を表します。
Shapley値は、特徴(i)が他の特徴とどのように相互作用しているかを示すために使用されます。特徴の順番に依存せず、特徴が共同で予測にどれだけ貢献しているかを公平に評価することができるため、特徴の重要度を正確に測定するのに役立ちます。