
9.深層学習の適用方法-物体検知
Mask R-CNN(Mask Region-based Convolutional Neural Network)は、物体検出とインスタンスセグメンテーションを同時に行うためのディープラーニングベースのモデルです。
Mask R-CNNは、Faster R-CNNのアーキテクチャを基にしており、物体のバウンディングボックスの予測に加えて、各物体領域内のピクセルレベルのセグメンテーション(マスク)を生成します。
Mask R-CNNの主な特徴は次のとおりです:
- 物体検出とインスタンスセグメンテーションの統合:Mask R-CNNは、物体の位置とクラスだけでなく、各物体領域のピクセルレベルのセグメンテーションも同時に行います。これにより、物体の領域内の詳細なセグメンテーション情報が得られます。
- バウンディングボックス予測とクラス分類:Mask R-CNNは、各物体領域に対してバウンディングボックスの予測とクラス分類を行います。これにより、物体の位置と種類を特定することができます。
- ピクセルレベルのセグメンテーション:Mask R-CNNは、各物体領域内のピクセルごとにセグメンテーションマスクを生成します。このマスクは、物体の領域を高精度に特定し、ピクセルごとのセグメンテーションを提供します。
Mask R-CNNは、物体検出とセグメンテーションの統合により、高度な物体検出と詳細なインスタンスセグメンテーションを実現します。さまざまなコンピュータビジョンのタスクで広く使用され、精度と性能の両方で優れた結果を示します。
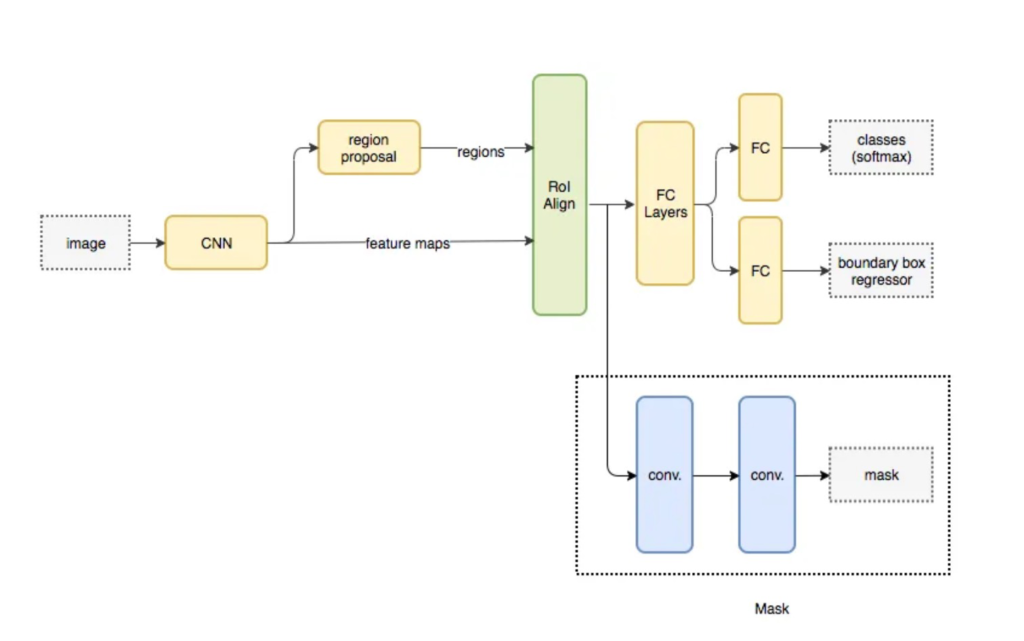
Mask R-CNNのネットワーク構成は、主に以下のコンポーネントで構成されています:
- Backbone Network:
- Mask R-CNNは、一般的には事前に学習された畳み込みニューラルネットワーク(CNN)をバックボーンとして使用します。代表的なバックボーンとしては、ResNetやResNeXtなどがあります。バックボーンは、入力画像から特徴マップを抽出するために使用されます。
- Region Proposal Network (RPN):
- RPNは、バックボーンの特徴マップ上で物体領域(バウンディングボックス候補)を提案します。RPNは、バウンディングボックスの位置とオブジェクトの存在スコアを予測するための一連の畳み込み層から構成されます。
- RoI Align:
- RoI Alignは、RPNによって提案された物体領域を特徴マップ上の固定サイズの領域(通常は14×14ピクセル)に変換します。この変換により、物体の位置情報を保持したまま、物体のサイズを正規化します。
- RoI Head:
- RoI Headは、RoI Alignで得られた特徴を入力として、物体のクラス分類とバウンディングボックスの微調整を行います。通常、クラス分類には全結合層とsoftmax活性化関数が使用され、バウンディングボックスの微調整には全結合層が使用されます。
- Mask Head:
- Mask Headは、RoI Headからの特徴を入力として、各物体領域のピクセルごとのセグメンテーションマスクを生成します。通常、Mask Headは畳み込み層、逆畳み込み層、およびsigmoid活性化関数から構成されます。
これらのコンポーネントが組み合わさり、Mask R-CNNは物体検出とインスタンスセグメンテーションを統合したネットワークを形成します。バックボーンネットワークによる特徴抽出、RPNによる領域提案、RoI AlignとRoI Headによるクラス分類とバウンディングボックス微調整、Mask Headによるセグメンテーションマスク生成が、物体検出とセグメンテーションの主要な機能を担当します。