
“Instance Normalization”(Instance正規化)は、
深層学習モデルの最適化手法の一つで、ニューラルネットワークの各インスタンス(データポイント)ごとに入力データを正規化する手法です。
Batch正規化やLayer正規化とは異なり、ミニバッチや各レイヤー単位ではなく、
個々のデータポイントごとに正規化を行います。
以下にInstance正規化の要点を説明します。
Instance正規化のアルゴリズムは、主に以下の手順で行われます:
各インスタンスごとの平均と分散の計算:
各インスタンスごとに、同じ特徴に位置するデータの平均と分散を計算します。これにより、各データポイント内での特徴の分布を正規化します。
平均と分散の正規化:
計算された各インスタンスの平均と分散を使用して、各データポイントの特徴を正規化します。具体的には、各特徴に対して、以下の式に基づいて正規化を行います(\(\epsilon\)は数値安定性のための小さな値):
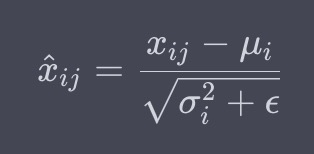
ここで、\(x_{ij}\)はデータポイントのi番目の特徴、\(\mu_{i}\)はi番目の特徴の平均、\(\sigma_{i}^2\)はi番目の特徴の分散です。
スケールとシフトの適用:
正規化されたデータに対して、スケール(スケーリング係数)とシフト(シフト係数)を適用して、変換されたデータを得ます。これにより、モデルがデータの変換を学習することが可能になります。
学習可能なパラメータの導入:
スケールとシフトのパラメータは、学習可能なパラメータとしてモデルに導入されます。これにより、ネットワーク自体がデータの正規化と変換を最適な形で学習することができます。
Instance正規化は、特にスタイル変換や画像生成などのタスクにおいて効果的であり、バッチサイズが小さい場合やデータポイント単位での正規化が求められる場合に使用されることがあります。