
本記事の範囲
4.開発・運用環境
ミドルウエアー深層学習ライブラリ
エッジコンピューティングー軽量なモデルーMobileNet
モデルの軽量化ー量子化、蒸留、プルーニング
分散処理ーモデル並列、データ並列
アクセラレーターデバイスによる高速化ーGPU
環境構築ーコンテナ型仮想化ーDocker
目次
ミドルウエアー深層学習ライブラリ
ディープラーニングに用いられる主要な深層学習ライブラリはいくつかあります。
- TensorFlow: Googleが開発したオープンソースの深層学習ライブラリであり、幅広いニューラルネットワークモデルを構築するための豊富な機能を提供しています。
- PyTorch: Facebookが開発したオープンソースの深層学習ライブラリであり、動的なニューラルネットワークの構築とデバッグに優れています。
- Keras: TensorFlowやTheanoをバックエンドとして使用することができる高水準のニューラルネットワークライブラリであり、使いやすさが特徴です。
- Caffe: コンバージェンスの高速化に焦点を当てたライブラリであり、特に画像分類や畳み込みニューラルネットワークに向いています。
これらは広く使用されているライブラリの一部であり、それぞれ独自の特徴や利点を持っています。プロジェクトのニーズや個人の好みによって、どのライブラリを選択するかは異なる場合があります。
Pytorchの基本の型
import torch
import torch.nn as nn
import torch.optim as optim
# ネットワークの定義
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.linear = nn.Linear(10, 1) # 入力次元数と出力次元数を指定
def forward(self, x):
x = self.linear(x)
return x
# データの準備
input_data = torch.randn(100, 10) # 入力データの作成
target = torch.randn(100, 1) # ターゲットデータの作成
# モデルのインスタンス化
model = NeuralNetwork()
# 損失関数と最適化アルゴリズムの設定
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 学習の実行
for epoch in range(100):
optimizer.zero_grad() # 勾配の初期化
output = model(input_data) # モデルの出力計算
loss = criterion(output, target) # 損失の計算
loss.backward() # バックプロパゲーション
optimizer.step() # パラメータの更新
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")
# 学習後のモデルを使用して予測を行う
input_data_test = torch.randn(10, 10) # テストデータの作成
output_test = model(input_data_test) # 予測の実行
print("Prediction:", output_test)
この例では、NeuralNetworkクラスを定義しています。このクラスはnn.Moduleを継承し、ネットワークの構造と順伝播関数(forward)を定義しています。
次に、入力データとターゲットデータを用意し、モデルのインスタンス化、損失関数の定義、最適化アルゴリズムの設定を行います。
その後、学習の実行部分では、エポック数だけループを回し、以下の手順を繰り返します:
- 勾配を初期化します(
optimizer.zero_grad()) - モデルに入力データを与えて出力を計算します(
output = model(input_data)) - 損失を計算します(
loss = criterion(output, target)) - バックプロパゲーションを実行します(
loss.backward()) - パラメータを更新します(
optimizer.step())
最後に、学習後のモデルを使用して新しいデータの予測を行います。この例ではinput_data_testを入力として与え、output_testに予測結果が格納されます。
MobileNet
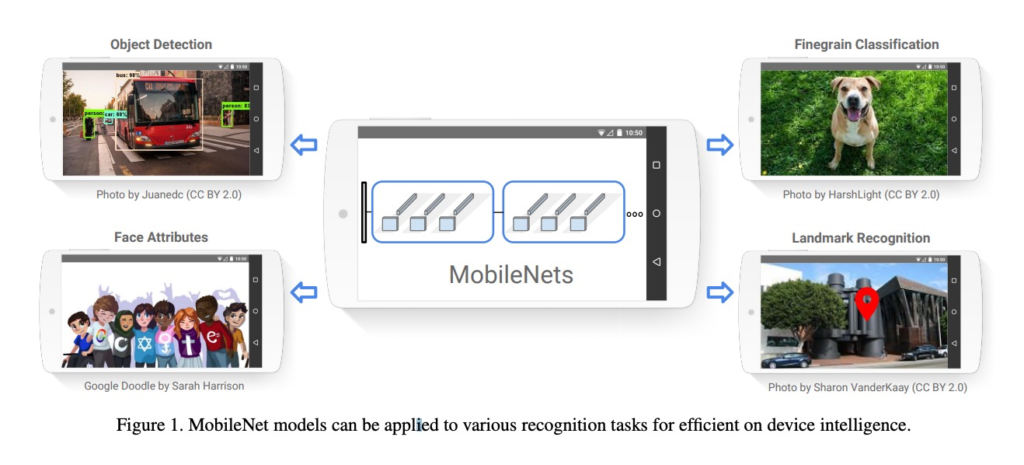
論文はこちら→ https://arxiv.org/pdf/1704.04861.pdf
論文より要約
MobileNetは、軽量なディープニューラルネットワークアーキテクチャであり、モバイルやエッジデバイスにおけるリソース制約のある環境で効率的に実行できます。モバイルアプリケーションにおいては、高速な推論速度と優れたパフォーマンスのバランスが求められます。MobileNetでは、深度方向と空間方向の畳み込みを分離する深度可分畳み込みを導入し、モデルサイズと計算量を劇的に削減しています。また、モジュール化されたアーキテクチャにより、さまざまな解像度や深さのネットワークをカスタマイズできます。MobileNetの実験結果から、他の重いモデルと比較して一部の性能が低下するものの、一般的なビジョンタスクにおいて優れた結果を示すことがわかります。
この要約では、MobileNetが軽量なディープニューラルネットワークアーキテクチャであり、深度可分畳み込みやモジュール化されたアーキテクチャを活用していることが強調されています。さらに、モデルのサイズと計算量を削減しながら、一般的なビジョンタスクで優れた結果を示すことが述べられています。
MobileNetは、コンピュータビジョンタスクにおける軽量なディープラーニングモデルの一つです。以下にMobileNetに関する要点を5つご紹介します:
- 軽量化のための深度可分離畳み込み:MobileNetでは、深度方向と空間方向の畳み込みを分離する深度可分離畳み込みが使用されます。これにより、より少ないパラメータと計算量で効率的なモデルを実現しています。
- モデルサイズの小ささ:MobileNetは、モデルのパラメータ数や計算量を極力減らすことに重点を置いています。これにより、モバイルデバイスやエッジデバイスなどのリソース制約のある環境でも効率的に動作することが可能です。
- モジュール化と柔軟性:MobileNetはモジュール化されたアーキテクチャを採用しており、異なる深さや解像度のネットワークを構築する際に柔軟性を提供します。これにより、異なるタスクやリソース要件に応じてモデルをカスタマイズできます。
- モバイルアプリケーションへの適用:MobileNetは、主にモバイルアプリケーションやリアルタイムのビジョンタスクに適しています。例えば、画像分類、物体検出、セマンティックセグメンテーションなどのタスクに利用されます。
- パフォーマンスと精度のバランス:MobileNetは、軽量化を追求しつつも一定の精度を維持することを目指しています。従来のより重いモデルと比較して一部の性能が犠牲になる場合もありますが、一般的に高速な推論速度と優れたパフォーマンスのバランスを実現しています。
これらの要点によって、MobileNetはリソース制約のある環境でのディープラーニングタスクの実行を可能にし、モバイルアプリケーションや組み込みシステムにおいて幅広い応用があります。
量子化
モデル軽量化の手法の一つとして、「量子化(Quantization)」があります。量子化は、ディープニューラルネットワーク(DNN)のパラメータや活性化値を浮動小数点数から整数や少ないビット数の浮動小数点数に変換することで、モデルのサイズや計算量を削減する手法です。
量子化の手法は以下のような手順で行われます:
- モデルのトレーニング: 通常の訓練手順でモデルをトレーニングします。これにより、通常の浮動小数点数でのパラメータと活性化値が得られます。
- 量子化の適用: トレーニング済みのモデルに対して、量子化手法を適用します。具体的な手法には、重みや活性化値を整数に量子化する整数量子化や、浮動小数点数を低ビット数の浮動小数点数に量子化する浮動小数点数量子化などがあります。
- 量子化後のパラメータと活性化値の格納: 量子化されたパラメータや活性化値は、整数や少ないビット数の浮動小数点数として格納されます。これにより、モデルのサイズが削減され、メモリ使用量が減少します。
- 推論の実行: 量子化されたモデルを使用して推論を実行します。この際、量子化されたパラメータと活性化値を使用して計算を行います。一部の量子化手法では、専用のハードウェアや特殊な演算命令を活用して、高速な推論を実現することができます。
量子化によって、モデルのサイズやメモリ使用量が大幅に削減されます。また、量子化による数値の制約や精度の低下は、一部のアプリケーションにおいてはほとんど影響を及ぼさないことが実証されています。そのため、リソース制約のある環境やエッジデバイスでのモデル展開において、量子化は有効な手法とされています。
量子化は、モデルの圧縮や高速な推論のためのモデル最適化の一環として広く利用されており、モデル軽量化の重要な手法の一つです。
蒸留
モデル軽量化の手法の一つとして、「蒸留(Knowledge Distillation)」があります。蒸留は、大規模な教師モデルから小規模な学生モデルを作成するための手法です。教師モデルの知識を学生モデルに「蒸留」することで、モデルのサイズや計算量を削減しつつも、性能の劣化を最小限に抑えることができます。
蒸留の手法は以下のような手順で行われます:
- 教師モデルのトレーニング: まず、大規模な教師モデルを訓練します。この教師モデルは、高い性能を持つ複雑なモデルであり、一般的にはより多くのパラメータとレイヤーを持っています。
- ソフトターゲットの生成: 教師モデルを使用して、訓練データセットまたは追加のデータセットに対する予測確率分布(ソフトターゲット)を生成します。ソフトターゲットは、教師モデルがクラスごとの確率を出力するようになっています。
- 学生モデルのトレーニング: 学生モデルは、教師モデルよりも小さいサイズを持つモデルです。学生モデルは通常、浅いネットワークや少ないパラメータを持つモデルです。学生モデルをトレーニングする際に、ソフトターゲットを使って教師モデルの知識を蒸留します。通常、ソフトターゲットと通常のハードターゲット(正解ラベル)の間の誤差を最小化することで学生モデルを訓練します。
蒸留によって、学生モデルは教師モデルの知識を効果的に学び、教師モデルと似た性能を持つことができます。学生モデルは教師モデルよりも小さく軽量であり、リソース制約のある環境やリアルタイムの応用に適しています。
蒸留は、高い性能を持つ大規模なモデルをデプロイする際のコスト削減や効率化を図るための重要な手法となっています。また、異なるタスク間での蒸留も研究されており、モデルの汎用性や転移学習の向上にも貢献しています。
プルーニング(枝刈り)
モデル軽量化の手法の一つとして、「プルーニング(Pruning)」があります。プルーニングは、訓練済みのディープニューラルネットワーク(DNN)から不要なパラメータや接続を削除することで、モデルのサイズや計算量を削減する手法です。
プルーニングの手法は以下のような手順で行われます:
- モデルのトレーニング: まず、通常の訓練手順でモデルをトレーニングします。この訓練では、通常の最適化手法(例:確率的勾配降下法)を使用して、損失関数を最小化するようにモデルのパラメータを更新します。
- パラメータの重要度の計算: トレーニングが終了した後、各パラメータの重要度を計算します。一般的な方法としては、各パラメータの勾配の絶対値や重みの絶対値を使用します。重要度の低いパラメータは、モデルの性能に対してほとんど寄与しないと見なされます。
- パラメータの削減: 重要度が低いパラメータを削除するか、ゼロに近い値に設定します。このような削減操作により、モデルのサイズが削減され、ゼロパラメータの存在により、実行時の計算量も削減されます。
- ファインチューニング: パラメータの削減後、モデルを再度トレーニングして、性能を回復させます。このステップでは、削減されたモデルのパラメータを調整し、性能の劣化を最小限に抑えます。
プルーニングは、訓練済みのモデルからパラメータを削減するため、モデルのサイズを大幅に減らすことができます。また、削減されたモデルは、リソース制約のある環境での展開や推論速度の向上にも役立ちます。
一般的には、モデルの重要な接続やパラメータは、訓練中により高い重みを持つ傾向があります。そのため、プルーニングは、モデルの学習と性能における重要な要素である重みのスパース性を活用することができます。
分散処理ーモデル並列ーデータ並列
- モデルのパラメータ数が多いほど、スピードアップの効率も向上する。
(jeffrey Dean et al.2016) Large Scale Distributed Deep Networks
- Large Scale Distributed Deep Networks
・Google社が2016年に出した論文
・Tensorflowの前身といわれている。
デバイスによる高速化ーGPU
CUDA
- CUDAはNVIDIAによって開発されたGPUプログラミングプラットフォームです。NVIDIAのGPU上で動作し、GPUを効果的に活用して並列計算を実行することができます。
- CUDAは専用の開発者向けツールキットやAPIを提供し、ユーザーがCUDA対応のGPUを活用して高速な数値計算やディープラーニングの演算を実行できるようにします。
- CUDAは高いパフォーマンスと柔軟性を提供し、ディープラーニングフレームワーク(例:TensorFlowやPyTorch)などのライブラリもCUDAをサポートしています。
OpenCL
- OpenCLはクロスプラットフォームの並列プログラミングフレームワークであり、異なるハードウェアやプラットフォーム上のGPUやCPUなど、さまざまなデバイスを活用して高性能な演算を行うことができます。
- OpenCLはベンダーによってサポートされており、異なるデバイス上での並列計算を統一的に扱うことができます。そのため、NVIDIAやAMDなどのさまざまなハードウェアベンダーがOpenCLをサポートしています。
- OpenCLはクロスプラットフォームの利点を持ち、異なるデバイスやプラットフォームで同じコードを使用して高性能な並列計算を実行できます。
CUDAとOpenCLは、GPUを活用して高性能な並列計算を行うためのプラットフォームとして広く使用されています。どちらを選ぶかは、使用するハードウェアやプラットフォーム、および利用するフレームワークやライブラリのサポートによって異なります。ただし、CUDAはNVIDIAのGPUに特化しているため、NVIDIAのGPUを使用している場合は、CUDAを活用することが推奨されます。
コンテナ型仮想化ーDocker
Dockerは、コンテナ型仮想化のためのオープンソースプラットフォームであり、ディープラーニングの利用において多くのメリットを提供します。以下にいくつかの主なメリットをご紹介します:
- 環境の再現性: Dockerは、コンテナ単位でアプリケーションや実行環境をパッケージ化します。これにより、ディープラーニングのモデルや環境を一貫した状態で再現することができます。異なる環境やデバイス上で同じDockerイメージを実行することで、統一された実行環境を確保できます。
- ポータビリティとスケーラビリティ: Dockerコンテナは軽量であり、異なる環境やプラットフォームで簡単に移動・展開できます。ディープラーニングモデルや環境をDockerコンテナにパッケージ化することで、柔軟にスケーリングやデプロイメントを行うことができます。クラウド環境やクラスター環境でのディープラーニングの管理が容易になります。
- 依存関係の管理: ディープラーニングのプロジェクトでは、さまざまなパッケージやライブラリ、バージョンの依存関係が発生することがあります。Dockerを使用することで、依存関係をDockerイメージ内に明示的に定義し、異なるプロジェクトや環境での依存関係の競合を防ぐことができます。
- セキュリティ: Dockerは独立したコンテナを提供するため、コンテナ間の相互干渉を防ぐセキュリティメカニズムがあります。ディープラーニングのプロジェクトにおいて、モデルやデータの保護、セキュリティ上のリスクの最小化が重要となります。Dockerは、セキュリティを強化し、コンテナ単位での分離を提供します。
これらのメリットにより、Dockerはディープラーニングのプロジェクトにおいて効果的なツールとなります。環境の再現性やポータビリティ、依存関係の管理、スケーラビリティ、セキュリティ強化など、より効率的かつ信頼性の高いディープラーニングの開発・展開をサポートします。